

What we want to achieve?
We at Altenar regularly facing a need of meeting regulator requirements. The latest requirement was to set up a MySQL DB replication to a DB that is located in a different region, however we could not rely on native replication features, because we want to omit some particular tables and stream only data that is required.
So we came up with an idea to produce data fr om the DB to Kafka and then to sink it to a destination DB. Using Kafka Connect, we can sel ect which DB and tables will be replicated, so no extra data will be leaked.
What is Debezium and why?
Debezium is a connector designed specifically for Kafka, which serves as a pluggable and declarative data integration framework for Kafka. With Debezium, you can effortlessly capture and stream changes fr om various databases, such as MySQL, to Kafka topics. This change data capture process enables your applications to respond promptly to inserts, updates, and deletes made in the source database.
By utilizing Debezium as a connector within Kafka Connect, you gain the ability to set up a replication pipeline that seamlessly transfers data fr om a source database, like MySQL, to a target database, ensuring consistency and accuracy. Debezium’s connector capabilities ensure that all events, even in the face of failures, are captured and reliably delivered to Kafka topics.
Architecture

Prerequisites
To follow the lab, you have to have:
- Confluent Kafka 7.5.x with Kafka Connect.
- MySQL 5.6 with enabled binary logs.
You can skip the following installation steps if you have already meet all requirements.
Installing Confluent Kafka
Deploy Kafka using Confluent Kafka Ansible playbooks available on GitHub.
For the demo you can deploy 3 VMs and install all roles on them, so each VM will have Broker, Connect, Kraft controller roles.
Also, you can spin up the whole infrastructure in docker containers using Debezium github examples, however they are not using features of ACL, SASL_SSL. So you will have to adapt their docker-compose on your own.
Installing mysql
You can deploy MySQL using Docker containers or run it on k8s. Here below manifests that you will need to apply against k8s cluster. In our case, it was GKE.
StatefullSet
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
namespace: mysql
spec:
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:5.6
name: mysql
volumeMounts:
- name: config-volume
mountPath: /etc/mysql/conf.d/
- name: pvc-mysql
mountPath: /var/lib/mysql
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: password
ports:
- name: tpc
protocol: TCP
containerPort: 3306
volumes:
- name: config-volume
configMap:
name: mysql-config
- name: pvc-mysql
persistentVolumeClaim:
claimName: pvc-mysql
Service
---
apiVersion: v1
kind: Service
metadata:
annotations:
cloud.google.com/load-balancer-type: Internal
networking.gke.io/internal-load-balancer-allow-global-access: "true"
name: mysql
namespace: mysql
labels:
app: mysql
spec:
selector:
app: mysql
ports:
- name: tcp
protocol: TCP
port: 3306
type: LoadBalancer
Secret
Password that will be used to connect to the MySQL instance as root user.
--- apiVersion: v1 data: password: MTIzNDU2Nzg= # here is based64 root password which is 12345678 kind: Secret metadata: name: mysql-secret namespace: mysql type: kubernetes.io/basic-auth
Configmap
Debezium reads binary logs, so make sure binary logs are enabled and uses ROW format, as it is only supported.
--- apiVersion: v1 kind: ConfigMap metadata: name: mysql-config namespace: mysql data: mycustom.cnf: | [mysqld] log-bin=mysql-bin server-id=100 binlog_format=ROW binlog_row_image=FULL
PVC
apiVersion: v1 kind: PersistentVolumeClaim metadata: annotations: volume.beta.kubernetes.io/storage-provisioner: pd.csi.storage.gke.io volume.kubernetes.io/storage-provisioner: pd.csi.storage.gke.io finalizers: - kubernetes.io/pvc-protection namespace: mysql name: pvc-mysql spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi storageClassName: standard volumeMode: Filesystem
Configure Mysql
1.Connect to the mysql pod.
kubectl exec -it -n mysql mysql-0 -- bash
2. Connect to MySQL, it will promt you for a password that you defined in k8s secret.
mysql -u root -p
3. Create a source databases and a table.
mysql> CRE ATE DATABASE mydatabase_source;
mysql> USE mydatabase_source;
mysql> CRE ATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(30) NOT NULL,
email VARCHAR(50) NOT NULL
);
4. Create a sink database. We will use the same MySQL instance for sink and source for test purposes.
mysql> CRE ATE DATABASE mydatabase_sink;
5. Check that bin logs are enabled.
mysql> show variables like '%bin%';
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/mysql-bin |
| log_bin_index | /var/lib/mysql/mysql-bin.index |
mysql> show binary logs;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000001 | 65402 |
| mysql-bin.000002 | 1410954 |
| mysql-bin.000003 | 4115961 |
| mysql-bin.000004 | 722 |
| mysql-bin.000005 | 143 |
| mysql-bin.000006 | 7657 |
| mysql-bin.000007 | 125246 |
| mysql-bin.000008 | 143 |
| mysql-bin.000009 | 120 |
+------------------+-----------+
9 rows in set (0.00 sec)
Configure Kafka Connect
Next operations you need to perform on each node, that is somehow Kafka Connect can make replication pipeline reliable and highly available.
1.Ensure that Kafka Connect uses distributed config connect-distributed.properties.
grep distributed /usr/lib/systemd/system/confluent-kafka-connect.service
Description=Apache Kafka Connect - distributed
ExecStart=/usr/bin/connect-distributed /etc/kafka/connect-distributed.properties
2. Check that connect uses JsonConverter. Ensure that the following parameters are set in connect-distributed.properties
key.converter.schemas.enable: true
value.converter.schemas.enable: true
internal.key.converter.schemas.enable: true
internal.value.converter.schemas.enable: true
internal.key.converter: org.apache.kafka.connect.json.JsonConverter
internal.value.converter: org.apache.kafka.connect.json.JsonConverter
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
3. Install connect plugins, but first check a dir location for plugins.
In our case it is /usr/share/java/connect_plugins
grep path connect-distributed.properties
plugin.path=/usr/share/java/connect_plugins
So Debezim plugins need to be put into /usr/share/java/connect_plugins
cd /usr/share/java/connect_plugins # installing a source plugin curl https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/2.3.4.Final/debezium-connector-mysql-2.3.4.Final-plugin.tar.gz -o debezium-connector-mysql-2.3.4.Final-plugin.tar.gz tar xvzf debezium-connector-mysql-2.3.4.Final-plugin.tar.gz # installing a sink plugin curl https://repo1.maven.org/maven2/io/debezium/debezium-connector-jdbc/2.2.1.Final/debezium-connector-jdbc-2.2.1.Final-plugin.tar.gz -o debezium-connector-jdbc-2.2.1.Final-plugin.tar.gz tar xvzf debezium-connector-jdbc-2.2.1.Final-plugin.tar.gz
4. Restart Kafka connect daemon.
systemctl restart confluent-kafka-connect.service
5. Check what interfaces Kafka Connect listens to.
In our case all interfaces.
ss -tulpen | grep 8083 tcp LISTEN 0 50 *:8083 *:* uid:989 ino:6997007 sk:1a v6only:0 <->
6. Check if plugins installed where localhost:8083 is your Kafka Connect listener.
curl -sS https://localhost:8083/connector-plugins -k | jq [ { "class": "io.debezium.connector.jdbc.JdbcSinkConnector", "type": "sink", "version": "2.2.1.Final" }, { "class": "io.debezium.connector.mysql.MySqlConnector", "type": "source", "version": "2.3.4.Final" }, ]
Both plugins are successfully installed.
7. Add required Kafka ACLs, where localhost:9092 is your Kafka Broker listener.
exampleserver — This topic prefix represents a logical name for our MySQL instance
schema-changes — This topic prefix reflects schema changes in the DB
The list of required ACLs.
### WRITE ### kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation Write --topic "schema-changes.exampleserver_source" kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation Write --resource-pattern-type PREFIXED --topic "exampleserver_source" kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation Write \ --topic "__debezium-heartbeat.exampleserver_source" ### DescribeConfigs ### kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation DescribeConfigs --topic "connect-cluster-configs" kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --cluster --operation DescribeConfigs kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --topic "connect-cluster-status" --operation DescribeConfigs kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --resource-pattern-type PREFIXED \ --topic "connect-cluster-offsets" --operation DescribeConfigs ### READ ### kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation Read --group "exampleserver_source" kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation Read --resource-pattern-type PREFIXED --topic "exampleserver_source" kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation Read --resource-pattern-type PREFIXED --topic "schema-changes" kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation Read \ --topic "__debezium-heartbeat.exampleserver_source" kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation Read --group "exampleserver_source-schemahistory" ### CREATE ### kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation Create --resource-pattern-type PREFIXED --topic "exampleserver_source" kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation Create --resource-pattern-type PREFIXED --topic "schema-changes" ### DESCRIBE ### kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --operation Describe --resource-pattern-type PREFIXED --topic "schema-changes" kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --cluster --operation Describe kafka-acls --bootstrap-server localhost:9094 \ --command-config client.properties \ --add \ --allow-principal User:kafka-connect \ --cluster --operation Describe \ --topic "__debezium-heartbeat.exampleserver_source"
7. Prepare json configuration for sink and source plugins.
source-mysql.json
SALS and SSL parameters can be checked in /etc/kafka/connect-distributed.properties.
{
"name": "mysql-source-connector",
"config": {
"heartbeat.interval.ms": "3000",
"autoReconnect":"true",
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"topic.prefix": "exampleserver_source", # prefix for topiucs
"database.hostname": "10.10.10.10", # DB host ip
"database.port": "3306",
"database.user": "root",
"database.password": "********",
"database.server.id": "1000",
"database.include.list": "mydatabase_source", # select a DB to replicate
"database.whitelist": "mydatabase_source", # monitor a DB
"table.include.list": "mydatabase_source.users", # choose which table to replicate
"topic.creation.enable": "true", # auto-create topics
"topic.creation.default.replication.factor": 3,
"topic.creation.default.partitions": 3,
"topic.creation.default.cleanup.policy": "compact",
"topic.creation.default.compression.type": "lz4",
"schema.history.internal.kafka.bootstrap.servers": "localhost:9094", # list of brokers
"schema.history.internal.kafka.topic": "schema-changes.exampleserver_source",
"schema.history.internal.consumer.security.protocol": "SASL_SSL",
"schema.history.internal.consumer.sasl.mechanism": "PLAIN",
"schema.history.internal.consumer.sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"*******\" password=\"*******\";",
"schema.history.internal.producer.security.protocol": "SASL_SSL",
"schema.history.internal.producer.sasl.mechanism": "PLAIN",
"schema.history.internal.producer.sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"*******\" password=\"*******\";",
"schema.history.internal.producer.ssl.truststore.location": "var/ssl/private/kafka_connect.truststore.jks",
"schema.history.internal.producer.ssl.truststore.password": "**************",
"schema.history.internal.consumer.ssl.truststore.location": "/var/ssl/private/kafka_connect.truststore.jks",
"schema.history.internal.consumer.ssl.truststore.password": "**************"
}
}
sink-mysql.json
{ "name": "mysql-sink-connector", "config": { "heartbeat.interval.ms": "3000", "autoReconnect":"true", "connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector", "tasks.max": "3", "connection.url":"jdbc:mysql://10.10.10.10:3306/mydatabase_sink", # specify sink DB "connection.username": "root", "connection.password": "*********", "ins ert.mode": "upsert", "delete.enabled": "true", "primary.key.mode": "record_key", "schema.evolution": "basic", "database.time_zone": "UTC", "auto.evolve": "true", "quote.identifiers":"true", "auto.create":"true", # auto create tables "val ue.converter.schemas.enable":"true", # auto reflect schema changes "value.converter":"org.apache.kafka.connect.json.JsonConverter", "table.name.format": "${topic}", "topics.regex":"exampleserver_source.mydatabase_source.*", # topics regexp to replicate "pk.mode" :"kafka" } }
8. Upload configs
You should get 200 HTTP status code. Upon uploading a config, Kafka checks MySQL connection and if all required parameters are filled in.
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" https://localhost:8083/connectors/ -k -d @sink-mysql.json HTTP/1.1 100 Continue HTTP/1.1 201 Created Date: Thu, 28 Sep 2023 14:41:43 GMT Location: https://localhost:8083/connectors/mysql-source-connector Content-Type: application/json Content-Length: 2361 Server: Jetty(9.4.51.v20230217)
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" https://localhost:8083/connectors/ -k -d @source-mysql.json HTTP/1.1 100 Continue HTTP/1.1 201 Created Date: Thu, 28 Sep 2023 14:41:43 GMT Location: https://localhost:8083/connectors/mysql-sink-connector Content-Type: application/json Content-Length: 2361 Server: Jetty(9.4.51.v20230217)
If you want to replace configurations, you can delete connectors and apply new configurations after
curl -X DELETE https://localhost:8083/connectors/mysql-source-connector -k
curl -X DELETE https://localhost:8083/connectors/mysql-sink-connector -k
Highly recommended to always tailing the log to monitor the status of Kafka Connect daemon and connectors.
tail -f /var/log/kafka/connect.log
9. Check connectors status.
Get a list of connectors first.
curl https://localhost:8083/connectors/ -k | jq [ "mysql-source-connector", "mysql-sink-connector" ]
Check status of connectors and workers.
curl https://localhost:8083/connectors/mysql-sink-connector/status -k | jq
{
"name": "mysql-sink-connector",
"connector": {
"state": "RUNNING",
"worker_id": "localhost:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "localhost:8083"
}
],
"type": "sink"
}
Our connector and worker are running.
However, It might fail due to multiple reason, then there will be the following output.
curl https://localhost:8083/connectors/mysql-sink-connector/status -k | jq { "name": "mysql-sink-connector", "connector": { "state": "RUNNING", "worker_id": "localhost:8083" }, "tasks": [ { "id": 0, "state": "FAILED", "trace": "io.debezium.DebeziumException: Unexpected error whil.........", "worker_id": "localhost:8083" } ], "type": "sink" }
Check the error trace and after restart the job with id 0.
curl -X POST https://localhost:8083/connectors/mysql-source-connector/tasks/0/restart -k
Perform tests
The setup is ready, so it is time to test.
1. Connect to the DB and ins ert a test val ue into the table.
use mydatabase_source;
INS ERT INTO users (name, email) VALUES ('John1', '[email protected]');
2. Right after, a topic with the name exampleserver_source.mydatabase_source.users should be automatically created and populated with the data.
This is a screenshot of a very useful web application that allows browsing Kafka Brokers — Kafka-UI.
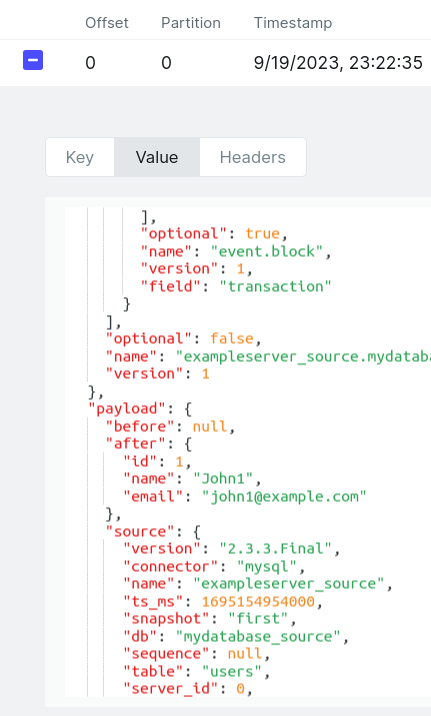
3. Then check sink DB mydatabase_sink if it gets new table with the data.
use mydatabase_sink; mysql> show tables; +----------------------------------------------+ | Tables_in_mydatabase_sink | +----------------------------------------------+ | exampleserver_source_mydatabase_source_users | mysql> sel ect * fr om exampleserver_source_mydatabase_source_users lim it 1; +----+-------+-------------------+ | id | name | email | +----+-------+-------------------+ | 1 | John1 | [email protected] | +----+-------+-------------------+
Replication is working.
4. However, you might notice that the name of the table is different. This is because plugin create a table based on topic name.
We can transform data adding to sink connector the following config and re-apply the config. Here we rewrite the name of topic and catch only first matching group (.*)
"transforms": "unwrap, rename", "transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState", "transforms.rename.type": "org.apache.kafka.connect.transforms.RegexRouter", "transforms.rename.regex": ".*\\.(.*)", "transforms.rename.replacement": "$1",
So instead of table name in sink database exampleserver_source.mydatabase_source.users connector will produce records to users.
However, the setting "auto.create":"true", that should create a table in a sink DB won’t do it for transformed val ue. So the table users will not be automatically created and you should create a table of upload a schema first.
Monitoring
This article will not cover monitoring in details, but strongly suggest considering setting up Prometheus and Alert-manager.
Kafka Connect is exposing metrics so they can be consumed by Prometheus directly.
Below is shown the most important alert that will check if any of Kafka Connect workers in Failed status. That will be enough to catch both sink and source connectors in failure.
---
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app: kube-prometheus-stack-operator
release: prometheus
name: kafka-connect-worker-failed
namespace: monitoring
spec:
groups:
- name: kafka
rules:
- alert: KafkaConnectWorkerFailed
expr: sum by (connector) (kafka_connect_connect_worker_metrics_connector_failed_task_count) > 0
for: 10s
annotations:
summary: 'Kafka connect plugin {{ $labels.connector }} has failed'
labels:
severity: criticalConclusion
The configuration that we built allows for seamless data integration and synchronization between the source and target databases. With the Kafka Connect Debezium sink/source connector, the data is then seamlessly transferred fr om source MySQL to Kafka and to MySQL sink database, enabling the replication of data in a controlled and efficient manner. This replication process ensures that all events are captured and reliably delivered, even in the face of failures.
You can also read this article on Medium in Alexander Murylev











